Setting up Databricks for data products
•
Stefan Vanraemdonck
Building secure data products on Databricks is difficult due to its generic nature and the many concepts involved.
Companies increasingly rely on data products for decision-making, insights, and AI/ML. data products separate data in meaningful entities with a purpose. More than ever, security, compliance, and governance are top concerns.
One of the popular data platforms is Databricks. Databricks is a platform that serves many use cases: Machine learning, data warehousing, data governance… Building secure data products on Databricks is difficult due to its generic nature and the many concepts involved: workspace access, secrets management, service principals, and user groups.
Lets try to map the features of a Data Product on Databricks.
Press enter or click to view image in full size
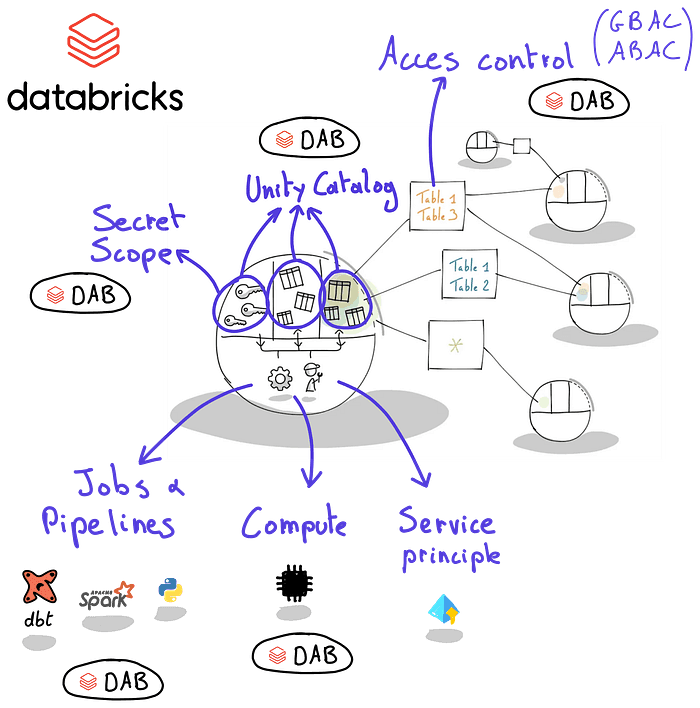
Databricks uses unity catalog to organize storage and access control. In a data product world, this enables separation between domains, data products and internal/external layers. It also allows organizing access control. For example: we can use a catalog to separate domains and schemas to separate data products. As a recommendation we propose to foresee an internal schema and an external schema per data product. Only the data in the external schema should be shared.
Databricks uses asset bundles to provide various types of resources. This allows the use of engineering best practices:we can define the resources as code and take advantage of version control and CI/CD. Most of the asset bundle resources can be mapped to data product elements:
Job orchestration
Compute infrastructure
Storage infrastructure: Unity Catalog schemas and volumes can be provisioned as code
Access control: also privileges can be defined as code
Secret scopes: allow to store secrets, like an Azure keyvault. The secrets typically contain credentials to access external systems
It looks like we can start implementing data products, right? But the devil is in the details. Let’s investigate some pain points:
Pain points
Let’s ask ourselves some straightforward questions.
How can we get full transparency on the cost of data products?
Depending on your company, this might be or not be an important topic. Lets separate the cost in 2 parts:
Storage costs: as the costs are related to the unity catalog and the unity catalog has a link to the data products, the link is straightforward.
Compute costs: This is less straightforward. When data products use job compute (for scheduled jobs), the DBUs can be linked to a data product (by the service principle, the name, tags…) On the other hand, when a developer works on multiple data products, it is very hard (not to say impossible) to link the compute costs to a data product. The only information you have is the identity and the cluster id. You could provide a cluster per data product, but nothing restricts the developer from using another cluster.
How can we make sure sensitive data cannot leak to no-authorized data products?
In this case, the same mechanism as above plays: when running scheduled jobs with service principles, access control can be enforced. But developers that have access to multiple data products can move sensitive data from one product to another.
How can we separate self service from platform services?
Databricks asset bundles are for self service and Terraform is for the platform team. I think this is a fair statement to make. Asset bundles allow users to define Databricks resources as code. Some examples
Schemas and volumes: this makes sense. Schemas and volumes are often the responsibility of the users.
Jobs and pipelines: same here. Orchestration is mostly in the hands of the users.
Grants: Asset bundles allow users to define grants. But there is a catch: grants are defining access between data products so you would expect to have this organized by the platform team.
Secret scopes: same here.
The underlying question is: what should be self service and what not. Furthermore, what tools should be used?
By now we see that the straightforward mapping of Databricks features onto the data product architecture is too simple.
The Fader Framework

As a basis for the framework, I want to introduce the platform fader knobs. Like in audio mixing boards, they define how much of the assets (tones) are passed to the consumer. Let’s make this more concrete:
The position of a platform fader defines how many instances of asset X a user can create in a self service manner
Some explanation:
Asset: this can be any asset in Databricks, e.g. service principles, workspaces, catalogs…
In a self service manner: this means that the user can set this up in a limited time (days) and without friction with the platform team (basically no discussion)
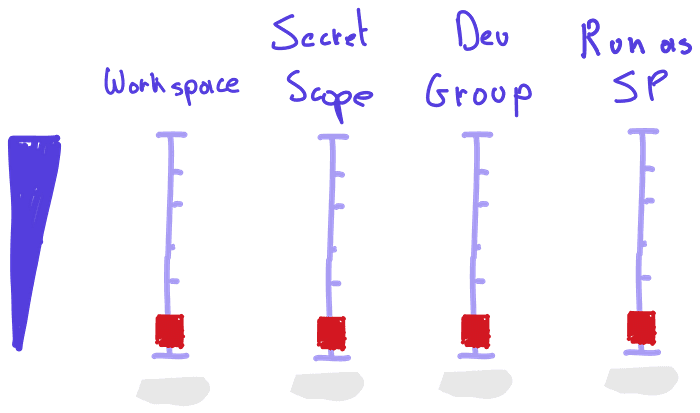
The picture below shows some examples. Moving the faders up means having more freedom as a user, moving down means less freedom:

With a developer group, we mean a group of identities with common privileges. Typically a developer group is linked to a repository and a service principle that is used for CICD in the examples below, we will take these together under the common term ‘developer groups’. We will also leave out:
Catalogs and schemas: we assume the user at least has the ability to make schemas. Having the ability to make catalogs gives added flexibility, but is not crucial.
Jobs: we also assume a user can create a job. If this is not the case not much can be done.
This brings us to the 4 main platform faders:
Workspaces: how strict can we make the separation between data products?
Secret Scopes: can we separate access to external systems?
Developer groups: can we separate development activities?
Service Principals: can we separate production activities?
Applying the framework
Minimal freedom setup
In this setup, the users get minimal freedom (one workspace, one service principle, one catalog…):
The architecture looks like this (the colored patches represent domains):
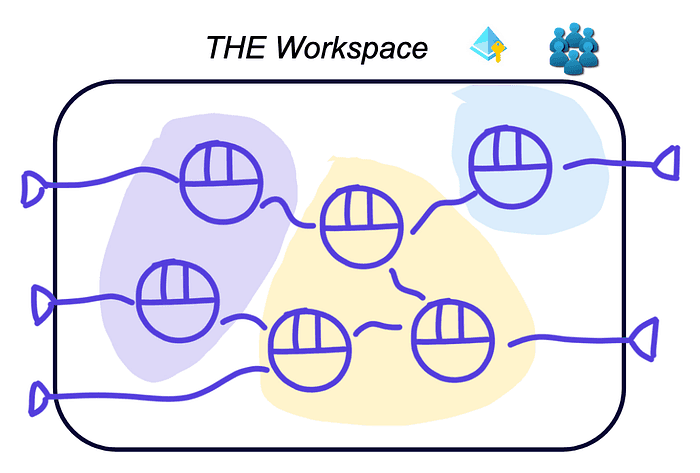
This setup means one space where all data products are developed. This might be easy for the platform team but is not really scalable to multiple use case teams developing many data products:
Cost tracking is not possible
No access control: all data products can consume from all data products
Unrestricted access to sources: all data products can consume from all sources
It can be a good way to get started on Databricks, using engineering practices, but it does not allow to scale.
Domain focussed setup
If your company has a heavy domain focus, this might be a good option
Press enter or click to view image in full size
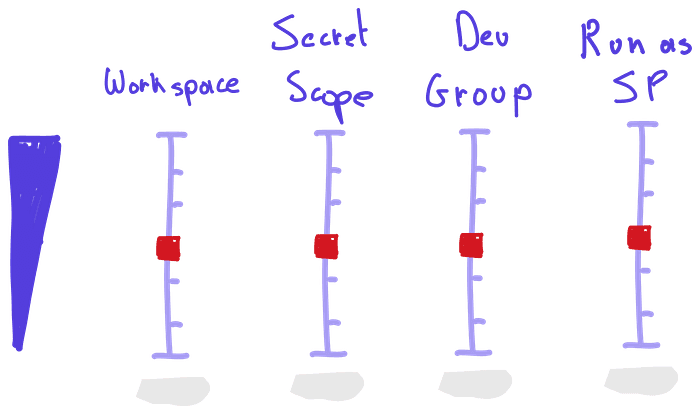
We organize the workspaces according to domains. The architecture looks like this:
Press enter or click to view image in full size
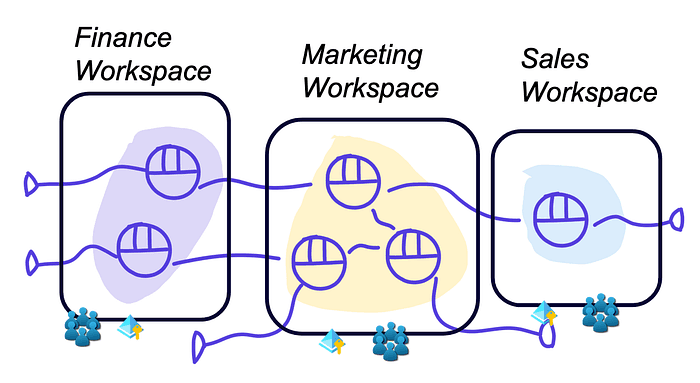
The separation of workspaces has the advantage that a user cannot see past the workspace boundaries. For example if the workspace has no access to sensitive data from another domain, the user in this workspace will also not have access. Some considerations:
If we assume that the domains are a stable concept in the organization, the workspace setup will be quite stable, hence limited work for the platform team.
We cannot enforce access control within a domain. If the domain team is central and well aligned, this can work. If the domain is not well organized, governance can become messy because there is not a lot that can be enforced.
To compensate for the freedom, I advise to increase the transparency. This allows us to detect possible issues. For example when a data product consumes unauthorized data.
Cost tracking between domains is possible. Compute (both job and all purpose) is linked to a workspace so developers cannot use the ‘wrong’ compute.
You could extend this setup with more separation between the data products (eg multiple service principles, secret scopes…).
Fully federated setup
If we want to have full separation, we need to put the sliders all the way up:
Press enter or click to view image in full size
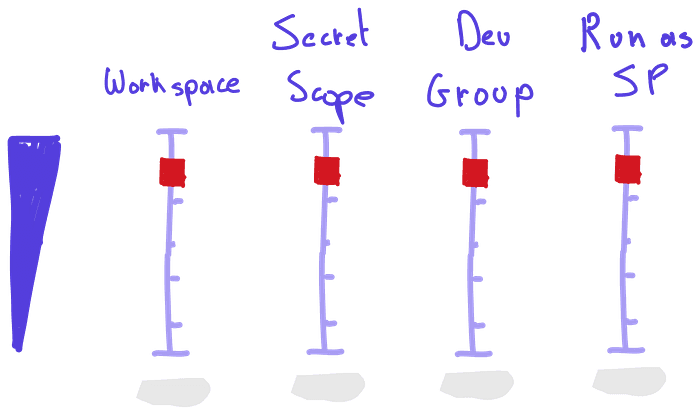
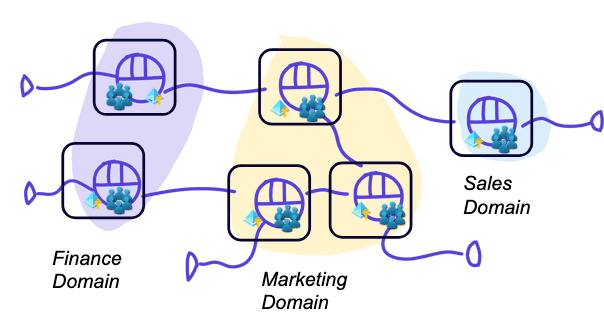
In this setup we have a full separation between data products. A data product is linked to a workspace so access control and resources can be separated (access to resources can be defined on workspace level). For example, cost can be perfectly tracked: a user working on data product x can only use compute from the workspace that is linked to that data product.
This federated setup comes with some disadvantages, for example:
The developer experience can get worse. If a user works on 2 data products in parallel, switching between workspaces is needed (switching in browser, databricks cli profiles…)
There is more overhead for the platform team. Creating a new data product entails creating a new workspace, compute, groups, service principles. Automation is a must
The amount of workspaces that can be created in a cloud region is limited to 1000. Taking into account a dev, qa and prod environment, this comes down to 333 data products.
Best practices
Some best practices when applying the framework:
Start simple. When you just get started you can use the minimal freedom setup. If you get the engineering principles right, you can change the setup at a later stage.
Audit your setup for the non-negotiables: if a data asset is super sensitive, make sure it cannot leak. Here you can use the domain focused setup.
Listen to the platform users: they define the added value of the data platform. If the developer experience is too difficult, make it easier.
Be transparent: explain the reason behind the architecture and why alternative solutions are not chosen. Here you can also use the fader framework.
Conclusion
As stated in the beginning, implementing data products on databricks is not straightforward. Databricks is an all purpose data platform trying to cover many purposes. By using the fader framework, you get concrete architectures that can be evaluated and implemented.
Latest

Data Platforms for humans
Data platforms fail when people are ignored. Why kindness and communication matter as much as architecture.

The Boring Stuff That Keeps You in the 5%
GenAI fails not because of models, but missing engineering, data, and product thinking. The “boring work” is what makes it real.

You Built a Data Mesh, But Your Metrics Are Still a Mess. Here’s Why.
Even with data mesh, metrics break: decentralized logic, no ownership, and cross-domain gaps. A semantic layer unifies KPIs.
