Wir helfen Ihnen, die Datenreifeleiter zu erklimmen.
Scaling for success with data and AI

Wir verleihen deinem Datenteam übernatürliche Fähigkeiten
Ihrem Datenteam übernatürliche Fähigkeiten für unvergleichliche Einblicke und Innovationen zu gewähren
Data Strategy
Eine solide Datenstrategie, -architektur und -infrastruktur ermöglichen es Organisationen, ihre Anstrengungen auf das Wesentliche zu konzentrieren, d.h. die Wertschöpfung.

Gen AI
GenAI bietet einen transformativen Weg für Unternehmen, der ihnen unvergleichliche Effizienz, Einsichten und Wettbewerbsvorteile verschafft.



93
Kunden
138
data initiatives delivered
400+
ausgebildete Personen
365+
Förderanlagenprojekte
Learning/Knowledge base
Tauchen Sie tiefer ein
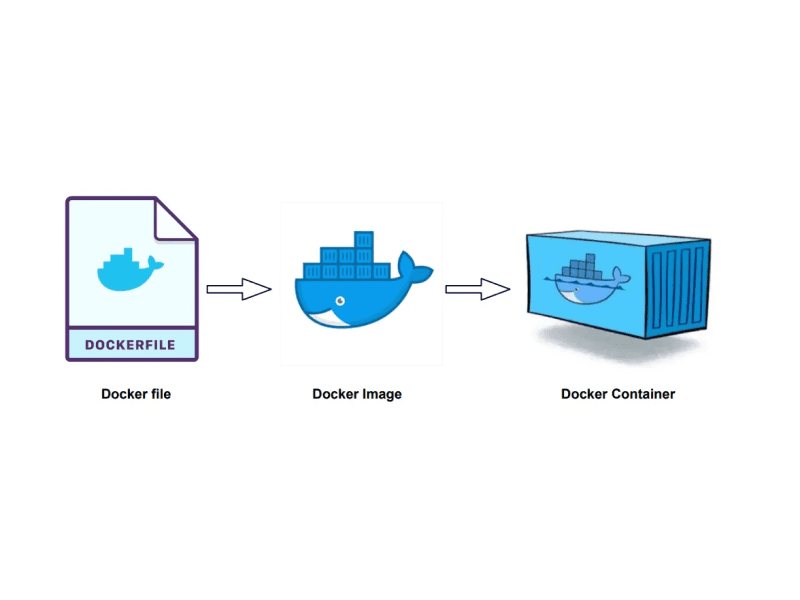
Wie wir unsere Docker-Bauzeiten um 40 % reduziert haben
Dieser Beitrag beschreibt zwei Möglichkeiten, das Erstellen Ihrer Docker-Images zu beschleunigen: den Build-Info remote zu cachen und die Link-Option beim Kopieren von Dateien zu verwenden.

Die Bausteine erfolgreicher Daten-Teams
Während meiner 7-jährigen Erfahrung im Bereich Daten habe ich in mehreren Datenteams gearbeitet, von denen einige erfolgreich waren, andere jedoch...
How to organize a data team to get the most value out of data
Offensichtlich ist: Ein Datenteam ist dazu da, dem Unternehmen Wert zu bringen. Aber ist das so offensichtlich? Haben Unternehmen nicht zu oft ein…
Learning/Knowledge base
Tauchen Sie tiefer ein

Rethinking the data product workbench in the age of AI
Rethinking how AI empowers data teams to build and maintain better data products without replacing them.

Episode 12. RADAR by publiq: How AI is Reshaping Cultural Discovery, Without Compromising Privacy
How Publiq uses AI and LLMs in RADAR to enrich cultural data and deliver smarter, privacy-first event recommendations.
When writing SQL isn't enough: debugging PostgreSQL in production
SQL alone won’t fix broken data. Debugging pipelines requires context, lineage, and collaborationnot just queries.

Episode 11. The Art of the Data Platform: Reducing Cognitive Load and Driving Adoption with Jelle De Vleminck
Lessons, mistakes & trends in building data platforms devs love, insights from Jelle De Vleminck for data leaders.

Episode 10. AI Innovation That Delivers: How to Align Strategy, Adoption, and Business Value with Joris Renkens
How can companies truly innovate with AI? Joris Renkens shares practical lessons on strategy, adoption, and building the right teams.

Episode 9. You Don’t Need the Latest Stack. You Need Better Questions. Episode with Rushil Daya & Kris Peeters
Learn to build high-performing data teams with agile practices, strong leadership, CI/CD, testing, mentoring, and collaboration.
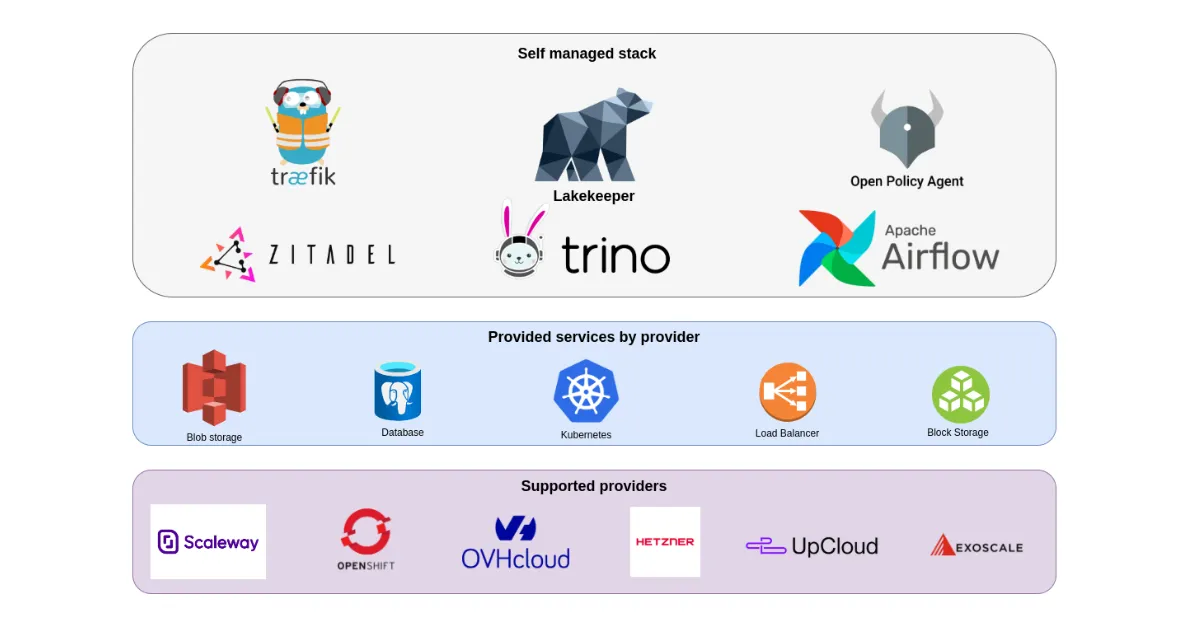
Portable by design: Rethinking data platforms in the age of digital sovereignty
Build a portable, EU-compliant data platform and avoid vendor lock-in—discover our cloud-neutral stack in this deep-dive blog.

Episode 8. What It Really Takes to Build a Data-Centric Organization, with Jonny Daenen & Kris Peeters
What does it take to build truly data-centric organizations?This episode goes beyond tools and dashboards to uncover lasting value.

European Clouds vs. Hyperscalers: Can You Really Build a Sovereign Data Platform?

Episode 7. Ein tiefer Einblick in SQLMesh: Strukturierte Abfragevalidierung und sicheres Pipeline-Testing mit Michiel De Muynck
Michiel De Muynck erkundet SQLMesh: semantische Schicht, virtuelle Datenumgebungen und Unit-Tests für SQL-basierte Analysen.

Cloud-Unabhängigkeit: Test eines europäischen Cloud-Anbieters gegen die Giganten
Kann ein europäischer Cloud-Anbieter wie Ionos AWS oder Azure ersetzen? Wir testen es – und finden überraschende Vorteile in Bezug auf Kosten, Kontrolle und Unabhängigkeit.

Episode 6. Data Mesh Live: Wie man es erfolgreich in Organisationen macht, mit Jacek Majchrzak & Andrew Jones
Kann Data Mesh Ihre Datenengpässe lösen? Nehmen Sie an unserem Seminar teil, um zu erfahren, wie Data Mesh Herausforderungen der Dezentralisierung und Skalierbarkeit angeht.

Episode 5: Jonas De Keuster deckt auf: Was an Datenmodellierung wirklich zählt – und was nicht
Entdecken Sie den Sinn und Unsinn der Datenmodellierung mit Jonas De Keuster (VaultSpeed) zu Automatisierung, Integration und Best Practices.

Episode 4: Zurück in die Cloud: Wie eine Behörde eine 14-Stunden-Migration reibungslos meisterte
Ein Regierungsauftraggeber ist zurück zur Cloud gewechselt. Die Standardisierung machte eine 14-stündige Big Bang-Migration sicher, nahtlos und praktisch unsichtbar.

Vermeide schlechte Daten von Anfang an
Das Erfassen aller Daten ohne Qualitätsprüfungen führt zu wiederkehrenden Problemen. Priorisieren Sie die Datenqualität von Anfang an, um nachgelagerte Probleme zu vermeiden.

Ein 5-Schritte-Ansatz zur Verbesserung der Datenplattform-Erfahrung
Verbessern Sie die UX der Datenplattform mit einem 5-Schritte-Prozess: Feedback sammeln, Benutzerreisen kartieren, Reibung reduzieren und kontinuierlich durch Iteration verbessern.

Episode 3. Nachhaltige Datenprodukte erstellen, die tatsächlich verwendet werden
Entdecken Sie, wie nachhaltige Datenprodukte echte Auswirkungen, dauerhaften Wert und bessere Geschäftsentscheidungen fördern – ohne unnötige Komplexität.

Episode 2. Was man nicht mit KI bauen sollte: Vermeidung der neuen technischen Schulden in datengestützten Organisationen
Warum die Beschleunigung von KI nach hinten losgehen kann: Lektionen über digitale Ausdehnung, Governance-Abwägungen und den Aufbau dessen, was in datengestützten Teams wirklich zählt.

29. April - Belgien dbt Meetup #10 (persönlich)
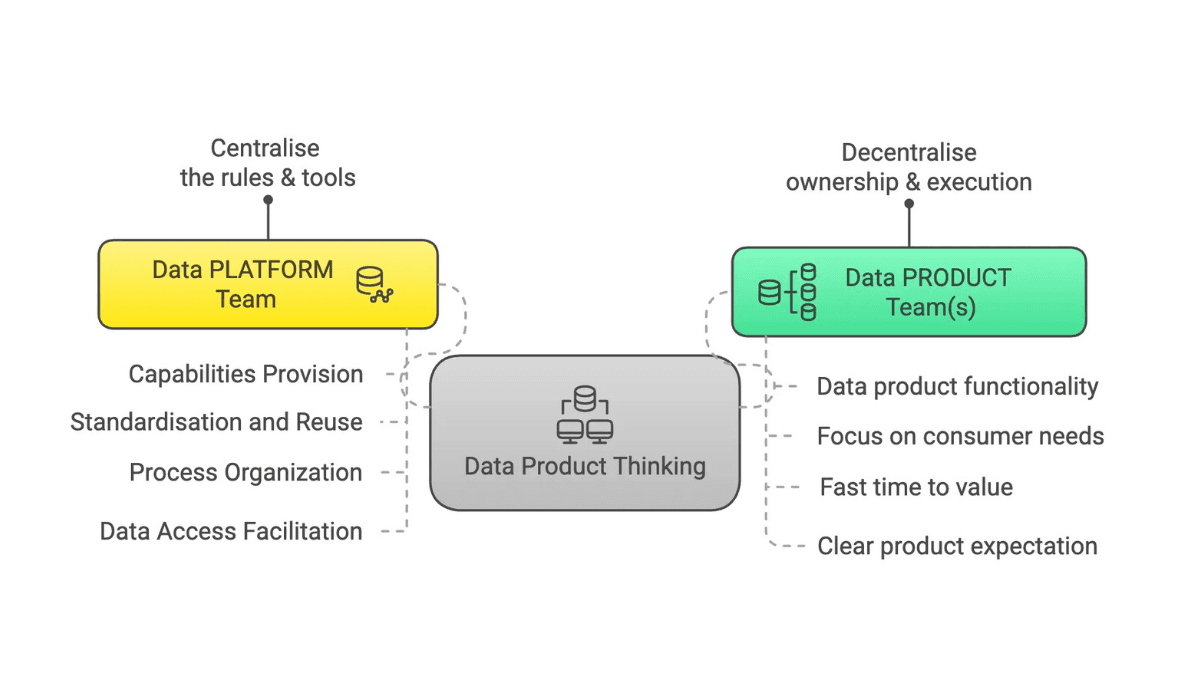
What Is Data Product Thinking?
Data Product Thinking treats data as a product, empowering domain teams to own, improve, and scale trusted, user-focused data assets.
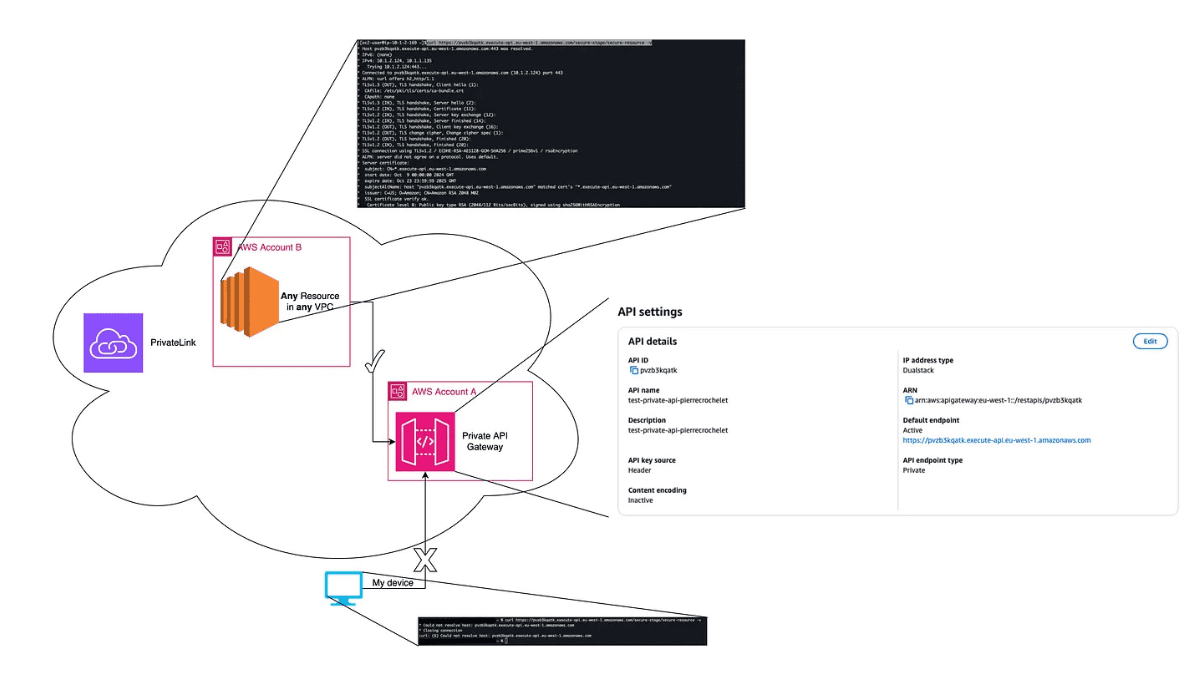
Why the ‘Private’ API Gateway of AWS Might Not Be as Secure as You Think
AWS Private API Gateways aren’t always private, misconfigs can expose access. Use resource policies to secure them properly.

Der Leitfaden des Data Engineers zur Optimierung von Kubernetes
Bei Conveyor haben wir über fünf Jahre daran gearbeitet, eine Batch-Datenplattform auf Basis von Kubernetes aufzubauen und zu betreiben.

Episode 1. Datenarchitektur von Grund auf neu aufbauen: Cloud, Data Mesh und die praktischen Abwägungen
Cloud vs On-Prem, US-Technologierisiken, Datenmesh, Teamdynamik und die verborgenen Kosten hinter „modernen“ Datenplattformen – harte Wahrheiten für Datenverantwortliche.

Integrating MegaLinter to Automate Linting Across Multiple Codebases. A Technical Description.
Automate code quality with MegaLinter, SQLFluff, and custom checks in Azure DevOps CI. Supports multi-language linting and dbt integration.

Vorherige Ausgabe: Stand der Daten 2025
Zustand der Daten – Eine Veranstaltung für Datenführer und Ingenieure zu KI, Datenplattformen, MLOps und Analytik. Veranstaltung verpasst? Sehen Sie sich die Aufzeichnungen an!

Sind Ihre AKS-Protokollierungskosten zu hoch? Hier erfahren Sie, wie Sie sie reduzieren können.
Bei Conveyor verwenden wir seit über 3 Jahren Azure Log Analytics, um Protokolle von unseren Kubernetes-Workloads, sowohl von Batch- als auch von langlaufenden Anwendungen, zu speichern.

Source-Aligned Data Products: The Foundation of a Scalable Data Mesh
Source-Aligned Data Products ensure trusted, domain-owned data at the source—vital for scalable, governed Data Mesh success.

Weltklasse Geschäftsführerveranstaltung in Frankfurt
Wir teilen praktische Einblicke, wie Organisationen skalierbare, self-service Datenplattformen etablieren können, um Effizienz und Eigenverantwortung zu fördern.
The State of Data Work in 2025: Insights From 32 In-Depth Conversations
Insights from 32 data professionals reveal 2025 challenges: balancing AI innovation, governance, quality, cost, collaboration, and literacy.

Dateningenieurwesen Winter Schule

Monitoring thousands of Spark applications without losing your cool
Monitor Spark apps at scale with CPU efficiency to cut costs. Use Dataflint for insights and track potential monthly savings.
Datenmodellierung in einer Datenproduktwelt
Viele Organisationen stoßen an die Grenzen der Datenlagerung, insbesondere wenn sie in der Größe wachsen.

SAP CDC with Azure Data Factory
Build SAP CDC in Azure Data Factory with SAP views, but high IR costs. Kafka + Confluent offers a cheaper, scalable alternative.

DAS DATA PRODUCT THINKING MEETUP - Dataminded Deutschland

Beyond the Buzzwords: Let’s Talk About the Real Challenges in Data
Cut through data buzzwords join honest chats with data pros to uncover real challenges, knowledge gaps & clever wins.

Daten im Gesundheitswesen erfolgreich umsetzen - Lektionen von der Frontlinie
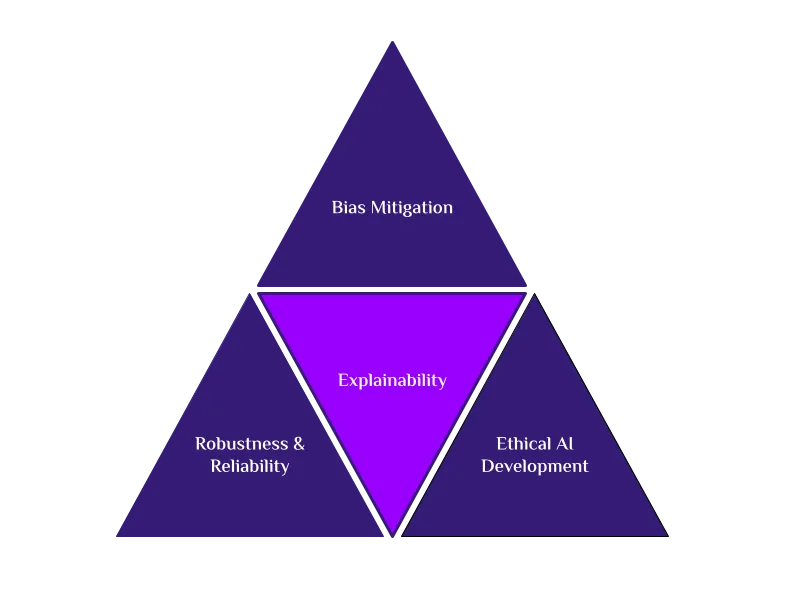
Von Gutem AI zu Gutem Data Engineering. Oder wie Verantwortungsbewusste AI mit Hoher Datenqualität zusammenwirkt.
Verantwortliche KI hängt von hochwertiger Datenverarbeitung ab, um ethische, faire und transparente KI-Systeme zu gewährleisten.

Ein Einblick in das Leben eines Datenführers
Datenführer stehen unter Druck, den Hype um KI mit der Organisation der Datenlandschaft in Einklang zu bringen. So bleiben sie fokussiert, pragmatisch und strategisch.

Dataminded Deutschland Meetup: DER DATEN-RITTER ⚔️🛡️
Über Medaillon: Wie man Daten für Self-Service-Daten-Teams strukturiert
Seit Jahren verlassen sich Datenplattformen – insbesondere Datenseen und Lakehouses – auf die Medaillonarchitektur.

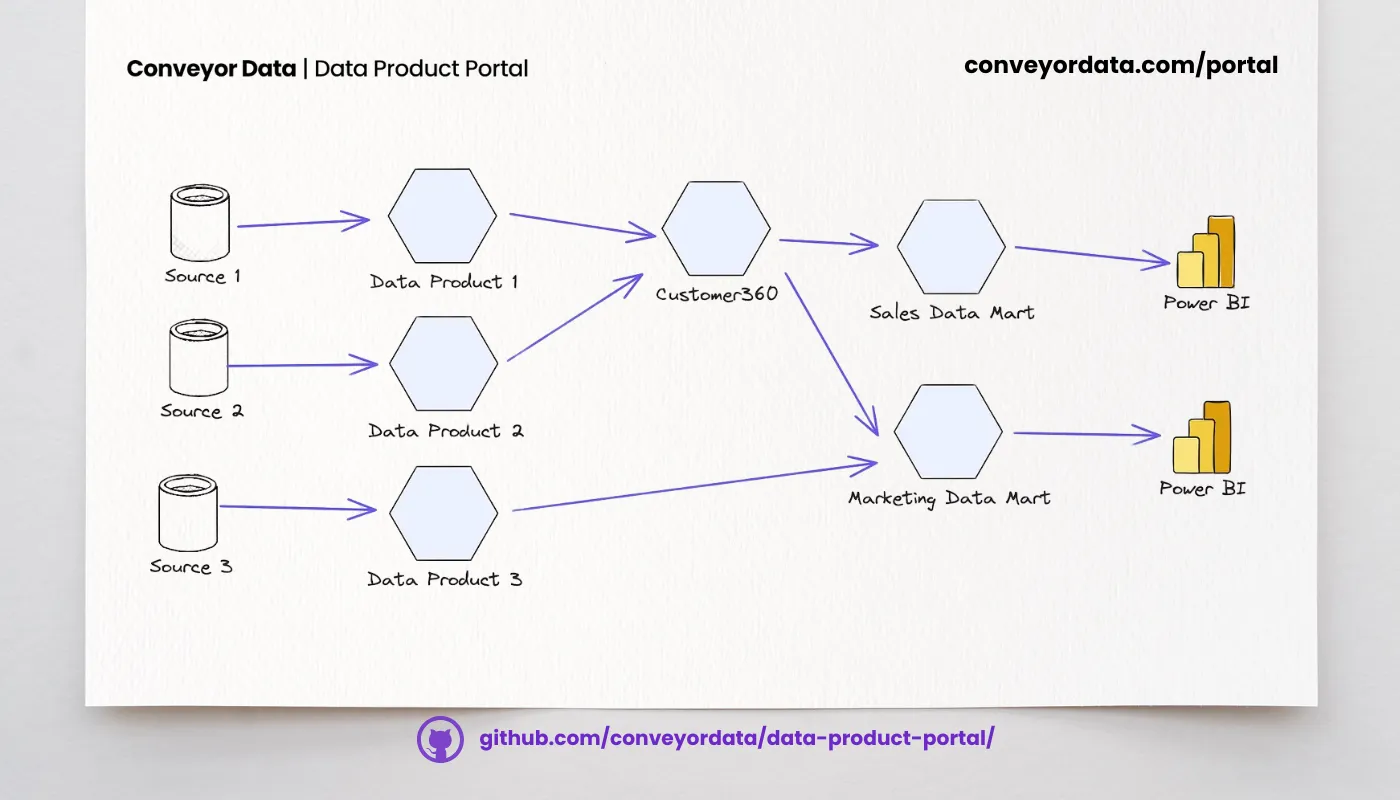
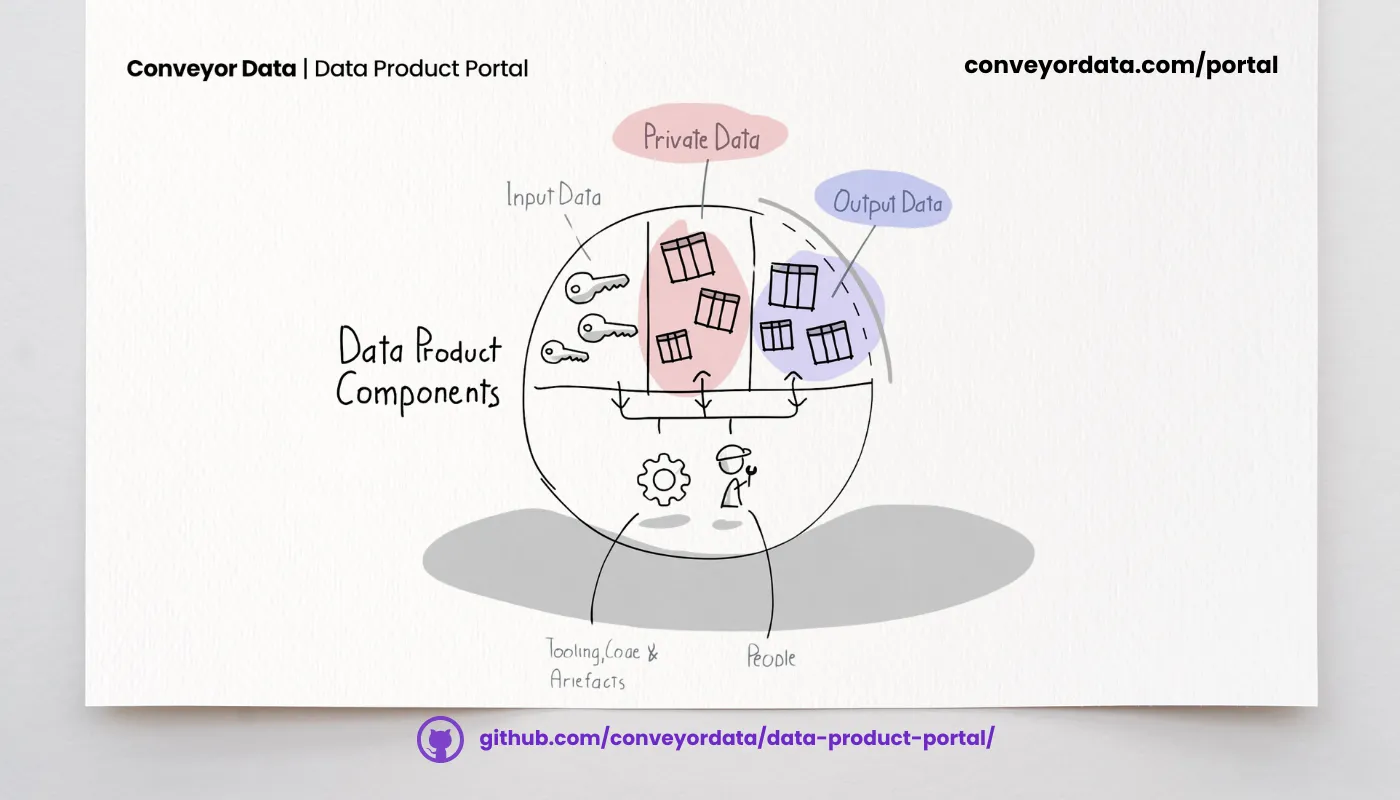
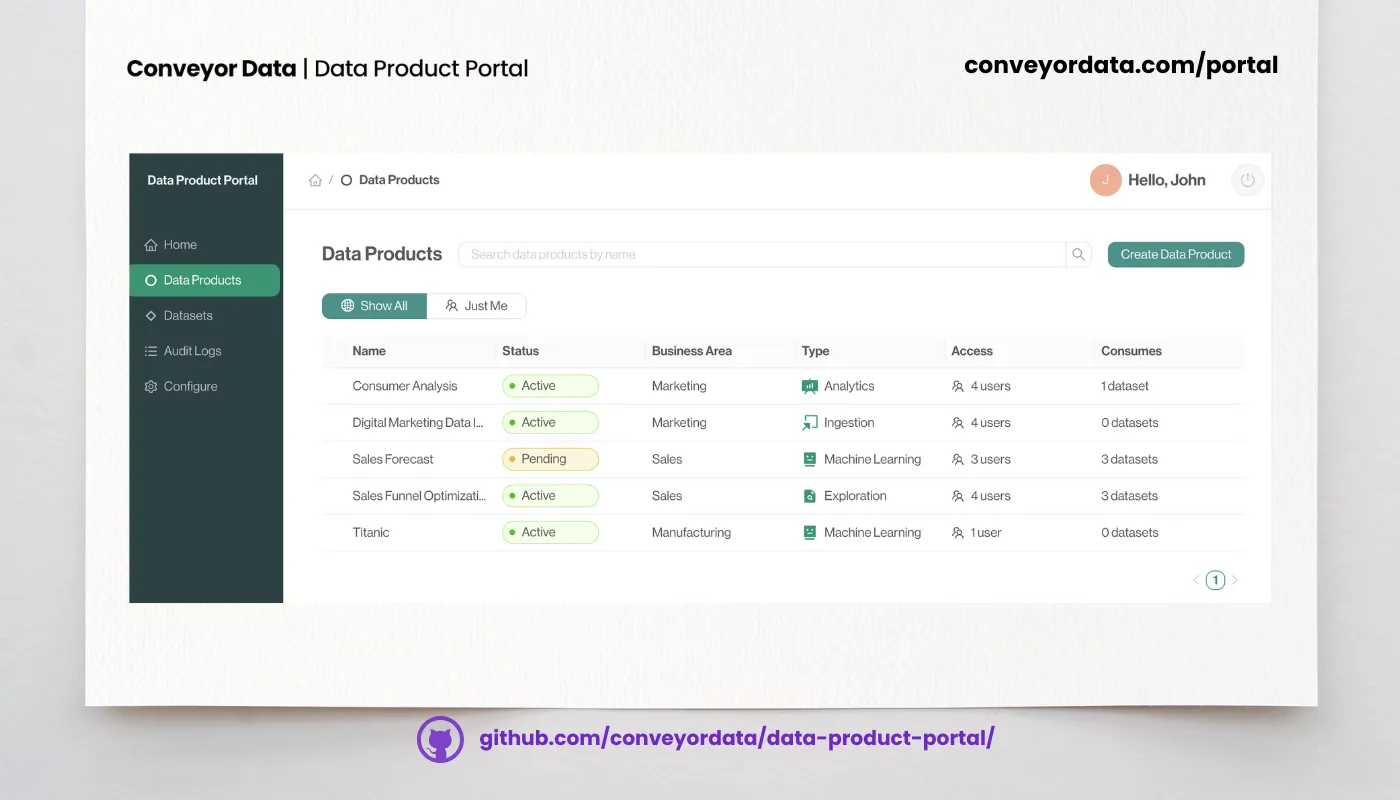
Jeden Nutzer stärken: Wie das Data Product Portal die Zusammenarbeit fördert
How we democratized data access with Streamlit and Microsoft-powered automation
Streamlit app + Power Automate = easy, self-serviced data access at scale, no YAML editing needed, just governance that actually works.
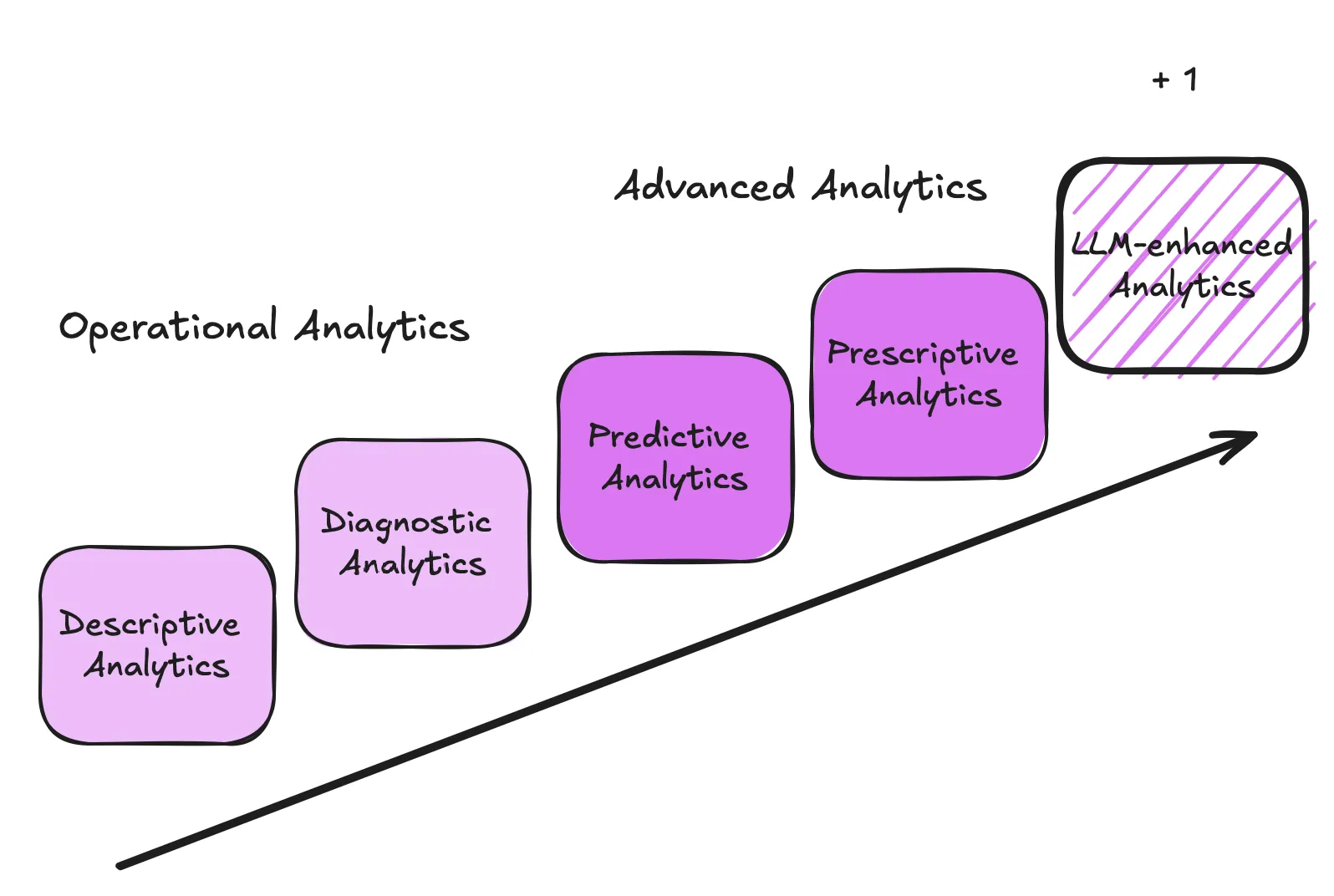
Unlocking the new Power of Advanced Analytics
Advanced analytics powered by LLMs and strong data engineering enables smarter predictions, deeper insights, and AI you can trust.

Datenverwaltung vereinfachen: Einführung des Datenproduktportals
Begleiten Sie uns zu einem exklusiven Webinar, das von Kris Peeters und Wannes Rosiers moderiert wird, während sie das Data Product Portal enthüllen.

Wie man die Komplexität des modernen Datenstapels bezwingt
Je mehr Menschen in einem Team sind, desto mehr Kommunikationslinien gibt es. Dasselbe gilt für die Werkzeuge in Ihrem Daten-Stack, die Komplexität skaliert schnell.

Webinar: "Erste Reaktionen: Markteinblicke zum Datenproduktportal"
Das Datenproduktportal integriert sich mit Ihrer bevorzugten Datenplattform.
Vor ein paar Wochen haben wir die Veröffentlichung des Data Product Portals als Open-Source-Repository angekündigt.
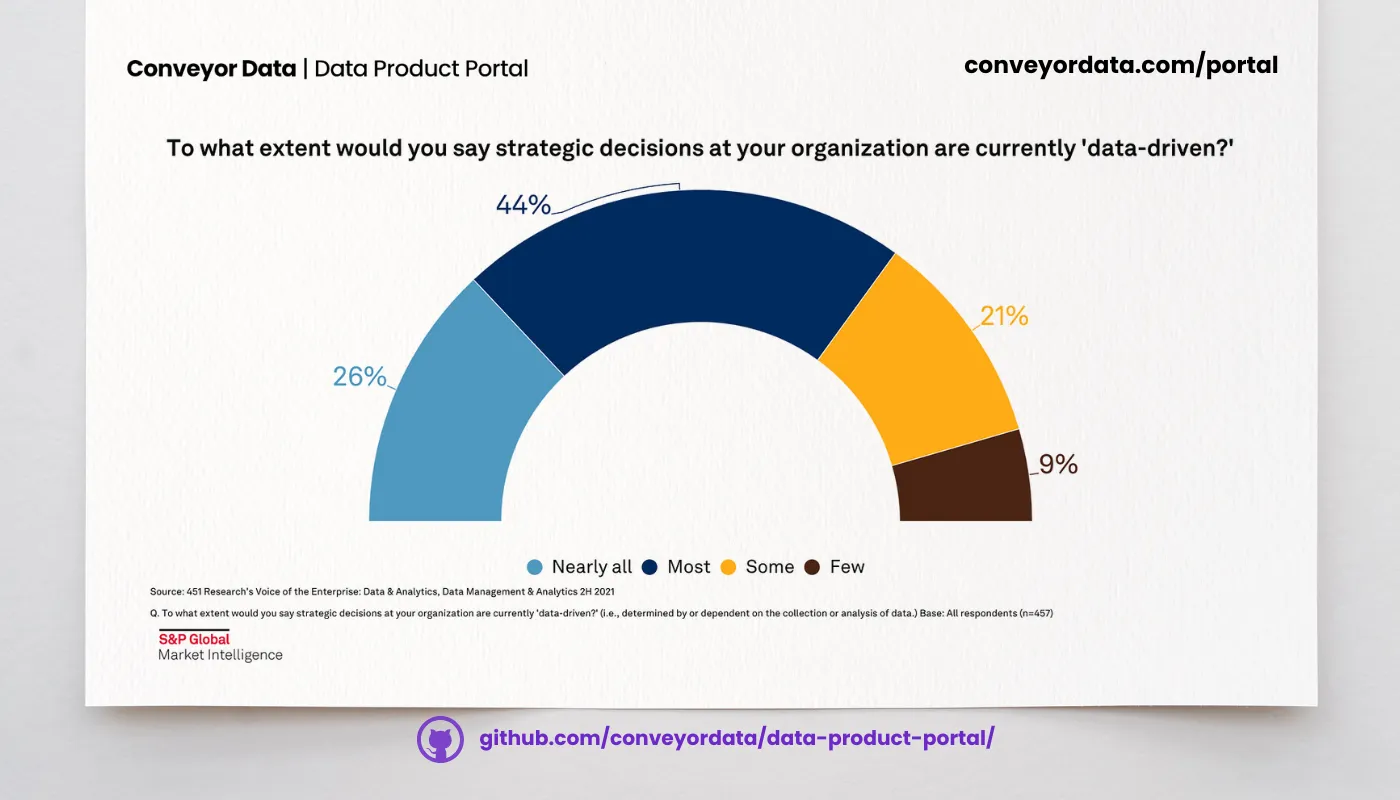
Wie man den Druck auf Ihre Daten-Teams verringert
Im August 2016 veröffentlichte BARC die Ergebnisse einer globalen Umfrage zum datengestützten Entscheidungsprozess in Unternehmen.
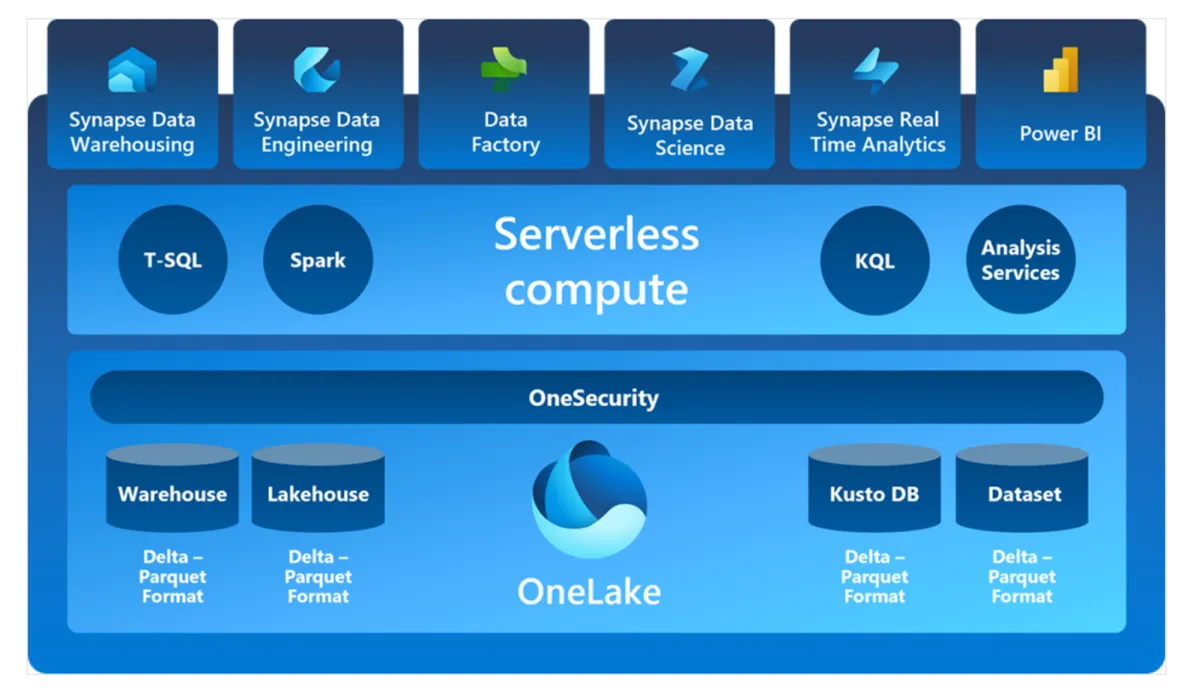
Microsoft Fabric’s Migration Hurdles: My Experience
Migrating to Microsoft Fabric?My experience shows it’s not ideal for modular platforms yet limited flexibility,IaC gaps & performance issues

Datenprodukt-Portal-Integrationen 2: Helm
Willkommen zur nächsten Folge unserer Serie über die Integrationen des Data Product Portals!

Datenstabilität mit Python: Wie man selbst die kleinsten Änderungen erfasst
Als Data Engineer ist es fast immer die sicherste Option, Daten-Pipelines alle X Minuten auszuführen. So können Sie nachts gut schlafen…

Warum Sie eine Benutzeroberfläche für Ihre Datenplattform erstellen sollten
Moderne Datenplattformen sind komplex. Wenn Sie sich Referenzarchitekturen ansehen, wie die von A16Z unten, enthält sie mehr als 30 Kästen.
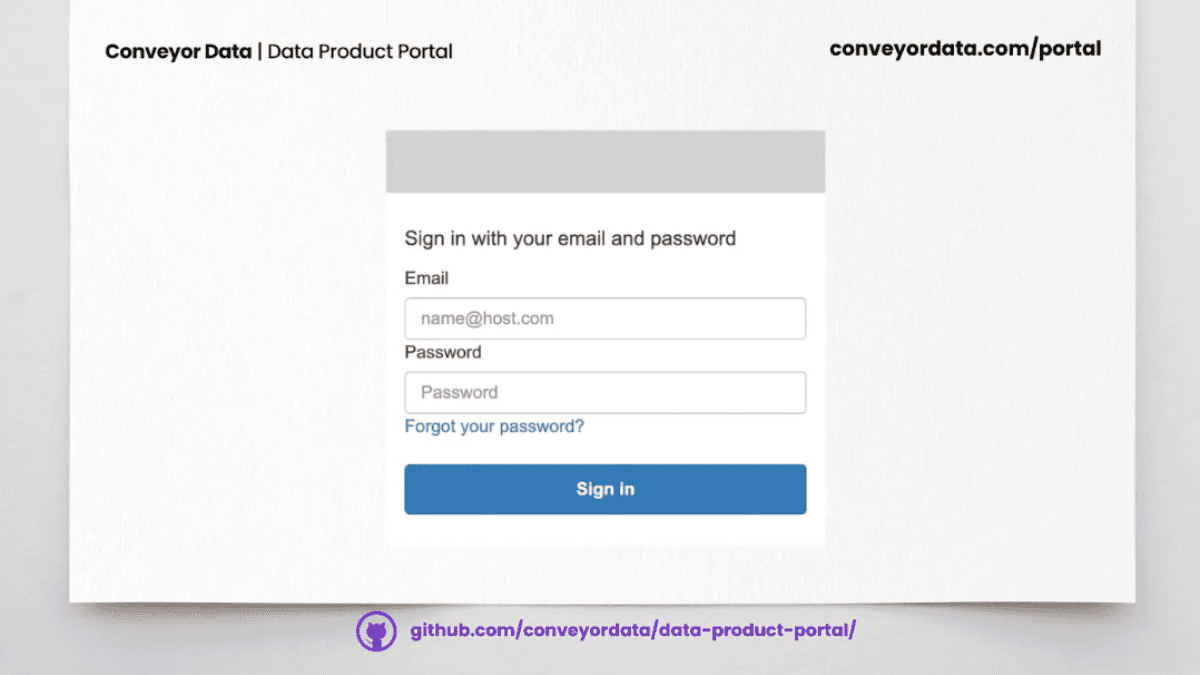
Datenprodukt-Portal-Integrationen 1: OIDC
Wie man Open ID Connect mit dem Data Product Portal integriert
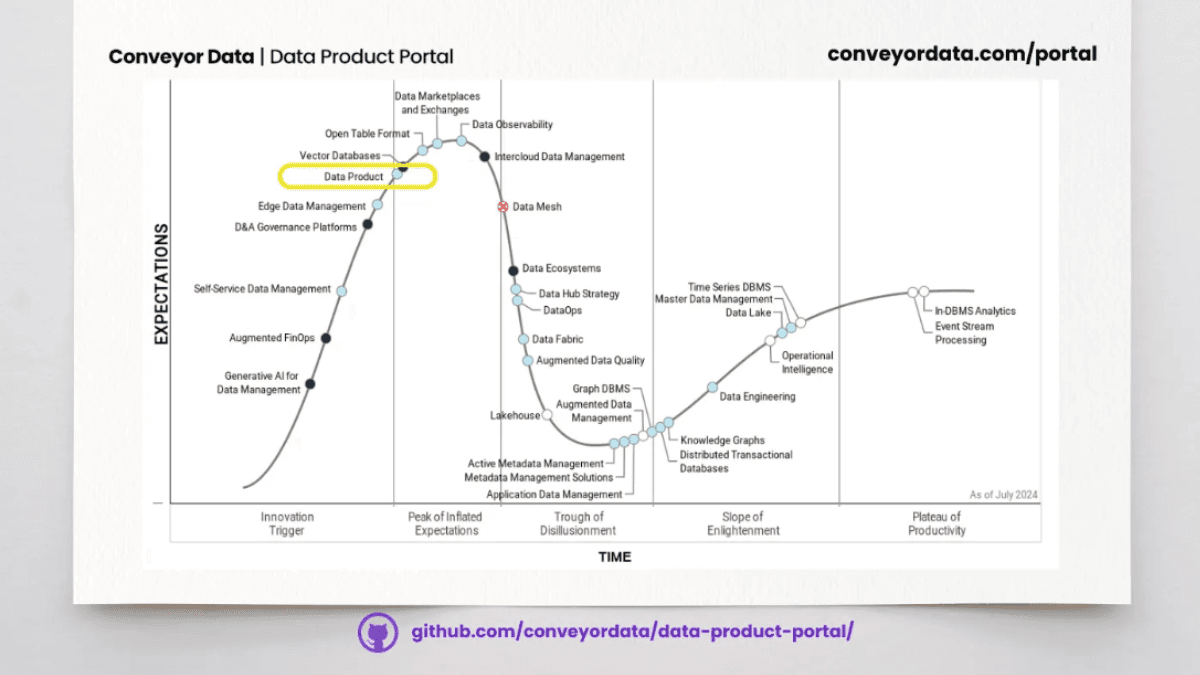
Der Stand der Datenprodukte im Jahr 2024
Gartner hat seinen Hype-Zyklus für Datenmanagement 2024 veröffentlicht.

Klare Signale: Verbesserung der Kommunikation innerhalb eines Datenteams
Clear team communication boosts data project success. Focus on root problems, structured discussions, and effective feedback to align better

Entmystifizierung des Geräteflusses
Implementierung des OAuth 2.0 Device Authorization Grant mit AWS Cognito und FastAPI
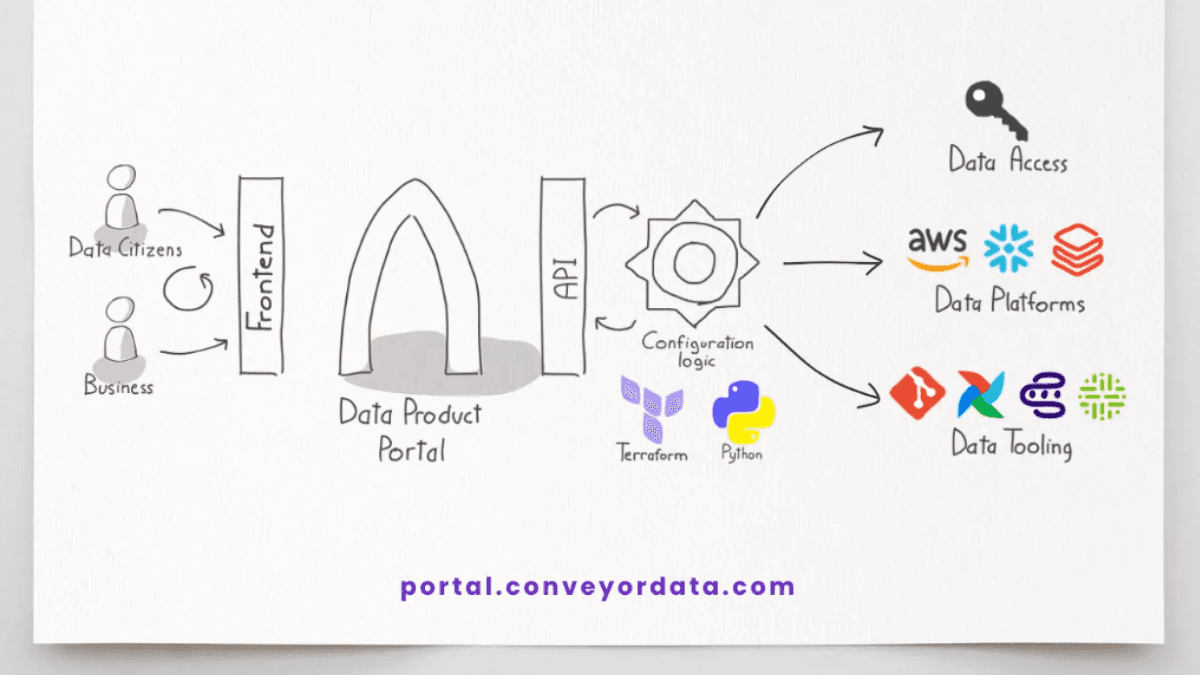
Einführung des Data Product Portal: Ein Open-Source-Tool zur Skalierung Ihrer Datenprodukte
In der sich schnell entwickelnden Welt der Daten stellen Unternehmen fest, dass der Schlüssel zum Erfolg beim Skalieren ihrer Daten

Die Auswirkungen des Produktdenkens auf Daten
Die Datenverwaltung hat sich im Laufe der Jahre verändert, und die Übernahme des Produktdenkens für Daten bringt erneut Veränderungen in die Daten...
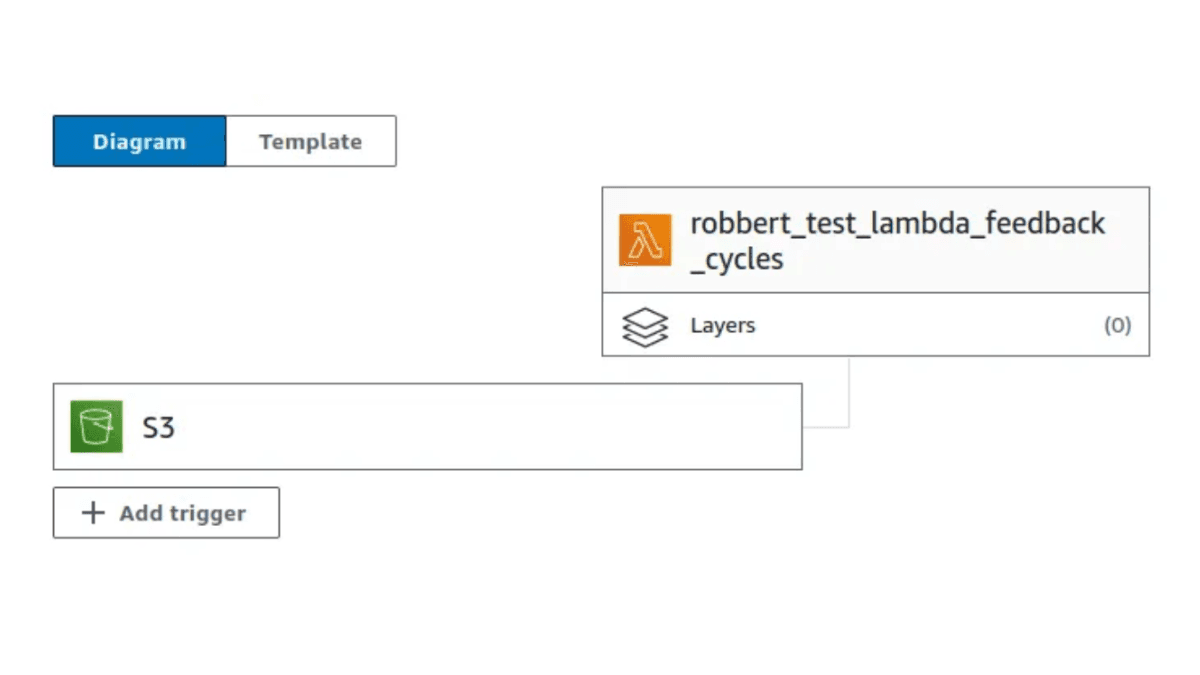
Kurze Feedbackzyklen auf AWS Lambda
Eine Makefile, die es ermöglicht, schnell zu iterieren

Nachhaltige GenAI: Technologie, Daten und Governance
Schließen Sie sich uns an für eine Veranstaltung, die sich auf die entscheidenden Aspekte der GenAI-Entwicklung und deren Implementierung konzentriert.
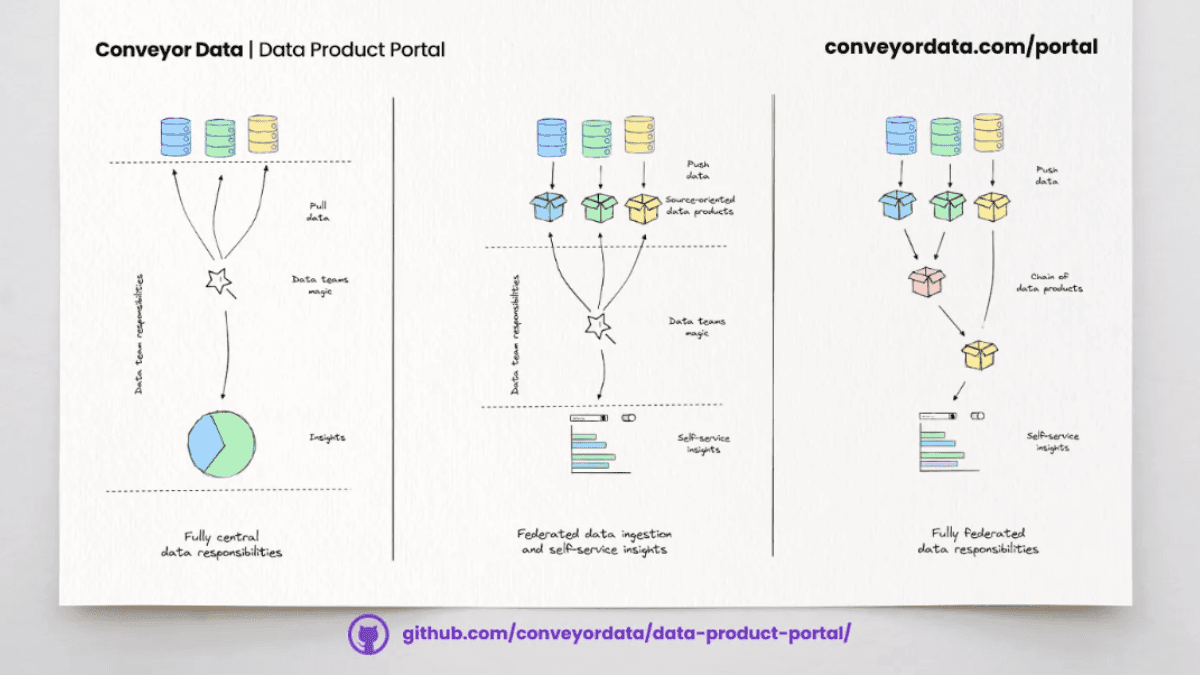
Das fehlende Stück zur Daten-Demokratisierung ist handlungsorientierter als ein Katalog.
Seit den neunziger Jahren, mit dem Aufkommen von Business Intelligence,

Prompt-Engineering für eine bessere SQL-Codegenerierung mit LLMs
Stellen Sie sich vor, Sie sind ein Marketing-Manager, der damit beauftragt ist, Werbestrategien zu optimieren, um verschiedene Kundensegmente effektiv anzusprechen…

Datenengineering-Sommerkurs 2024
Lerne Datenengineering von den Profis!

Alter der DataFrames 2: Polars Ausgabe
In dieser Veröffentlichung präsentiere ich einige Tricks und Funktionen von Polars.

Quack, Quack, Ka-Ching: Kosten senken, indem man Snowflake von DuckDB abfragt
Wie man Snowflakes Unterstützung für interoperable offene Lakehouse-Technologie — Iceberg — nutzen kann, um Geld zu sparen.

Die Bausteine erfolgreicher Daten-Teams
Basierend auf meiner Erfahrung werde ich die wichtigsten Kriterien für den Aufbau erfolgreicher Daten-Teams näher erläutern.

GenAI: Praktische LLM-Hackathon
Ein interaktives, praktisches Hackathon zum Erstellen und Bereitstellen einer kompletten LLM-basierten Anwendung von Anfang bis Ende.

Conveyor x Luminus Event: "Schnellster Weg zum Datenwert. Plattform- und Produktdenken umarmen"

Abfragen hierarchischer Daten mit Postgres
Hierarchische Daten sind weit verbreitet und einfach zu speichern, aber ihre Abfrage kann herausfordernd sein. Dieser Beitrag wird Sie durch den Prozess…

Sicher Snowflake von VS Code im Browser verwenden
Eine Hauptaktivität unserer Benutzer besteht darin, dbt innerhalb der IDE-Umgebung zu nutzen.

Die Vorteile eines Data-Platform-Teams
Seit Jahren bauen und nutzen Organisationen Datenplattformen, um Wert aus Daten zu schöpfen.

Wie man ein Datenteam organisiert, um den größten Nutzen aus Daten zu ziehen
Um das Offensichtliche zu sagen: Ein Datenteam ist dafür da, dem Unternehmen Mehrwert zu bieten. Aber ist das wirklich so offensichtlich? Haben Unternehmen nicht zu oft ein ...

Warum nicht Ihre eigene Datenplattform erstellen
Eine Zusammenfassung der Diskussion am runden Tisch über die Datenplattform von imec.

Clout* zertifiziert werden
Heiße Meinungen zu meinen Erfahrungen mit Cloud-Zertifizierungen
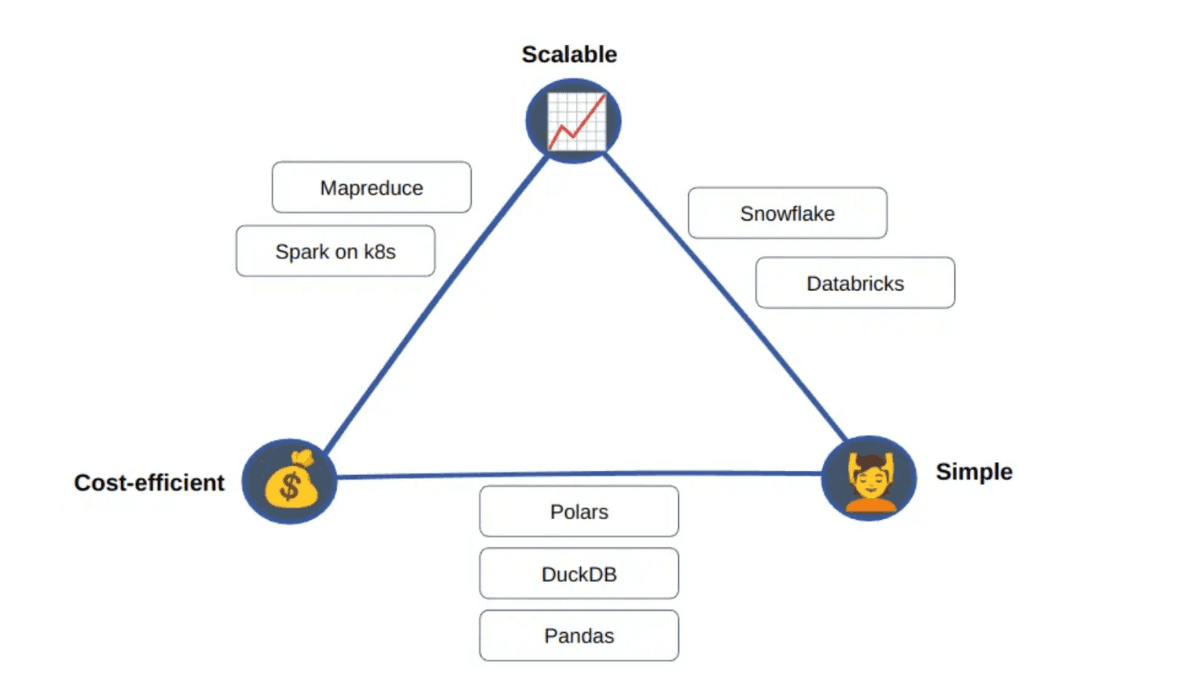
Sie können einen Supercomputer verwenden, um eine E-Mail zu senden, aber sollten Sie das?
Entdecken Sie die nächste Evolution der Datenverarbeitung mit DuckDB und Polars

Zwei Lifecycle-Richtlinien, die jeder S3-Bucket haben sollte
Abgebrochene Mehrteil-Uploads und abgelaufene Löschmarker: was sind sie und warum Sie sich wegen der schlechten AWS-Standarde darum kümmern müssen.

Dezentralisiert vs. Zentralisiert: Wie organisiert man seine Datenteams?

Wie wir GenAI genutzt haben, um die Regierung zu verstehen
Wir haben einen RAG-Chatbot mit AWS Bedrock und GPT-4 entwickelt, um Fragen zur flämischen Regierung zu beantworten.

My key takeaways after building a data engineering platform
Building a data platform taught me: deleting code is vital, poor design has long-term costs, and dependency updates are never-ending.

Leveraging Pydantic as a validation layer.
Ensuring clean and reliable input is crucial for building robust services.

Datenstand 2024

7 Lessons Learned migrating dbt code from Snowflake to Trino
Snowflake to Trino dbt migration: watch out for type casting, SQL functions, NULL order, and window function quirks.

Growing your data program with a use-case-driven approach
Use-case-driven data programs balance planning & building, enabling fast value, reduced risk, and scalable transformation.

Alle auf die Daten-Tanzfläche: eine Geschichte des Vertrauens
Wer bin ich, um zu argumentieren? Tatsächlich hatte ich das Privileg, einige Unternehmen in diese ganz besondere Ambition zu führen.

Quacking Queries in the Azure Cloud with DuckDB
DuckDB on Azure: fsspec works for now, but native Azure extension is faster—especially with many small files. Full support is on the way.

Zukunftssichere Datenengineering-Karriere. Essenzielle Fähigkeiten für 2024 und darüber hinaus
Begib dich auf eine Reise mit unseren erstklassigen Data Engineers, während sie die Schlüsselkompetenzen enthüllen, die die Zukunft des Data Engineerings gestalten werden.
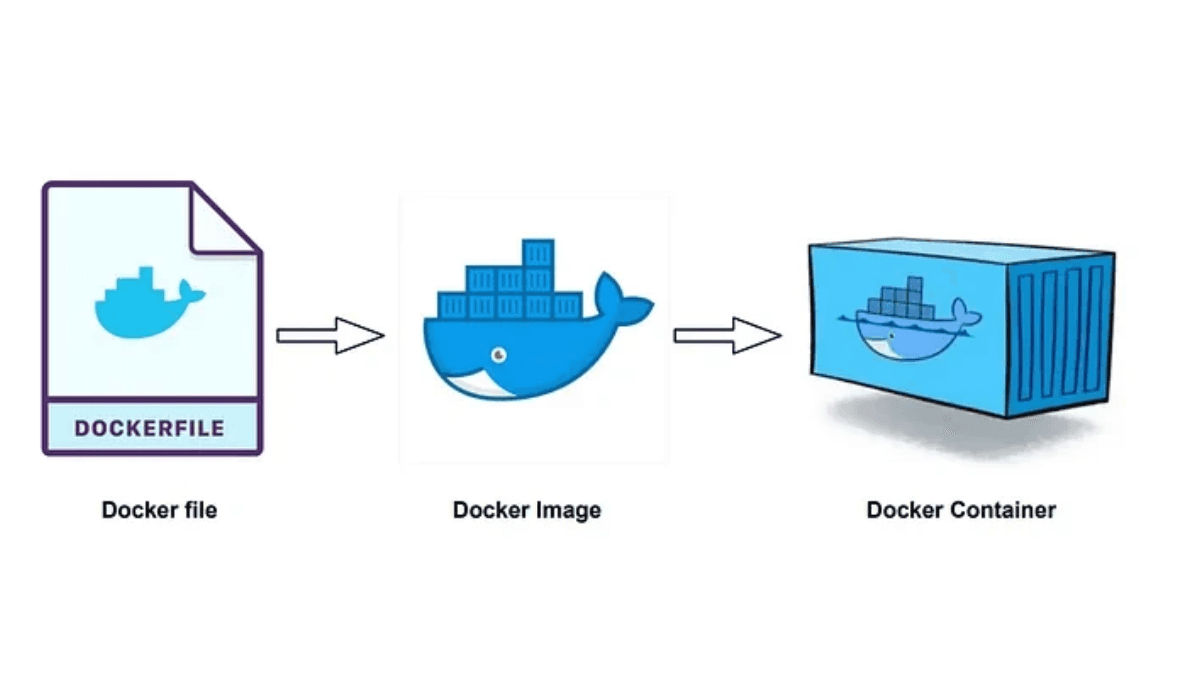
Wie wir unsere Docker-Bauzeiten um 40% reduziert haben
Dieser Beitrag beschreibt zwei Möglichkeiten, das Erstellen Ihrer Docker-Images zu beschleunigen: Das Caching von Build-Informationen remote und die Verwendung der Link-Option beim Kopieren von Dateien.
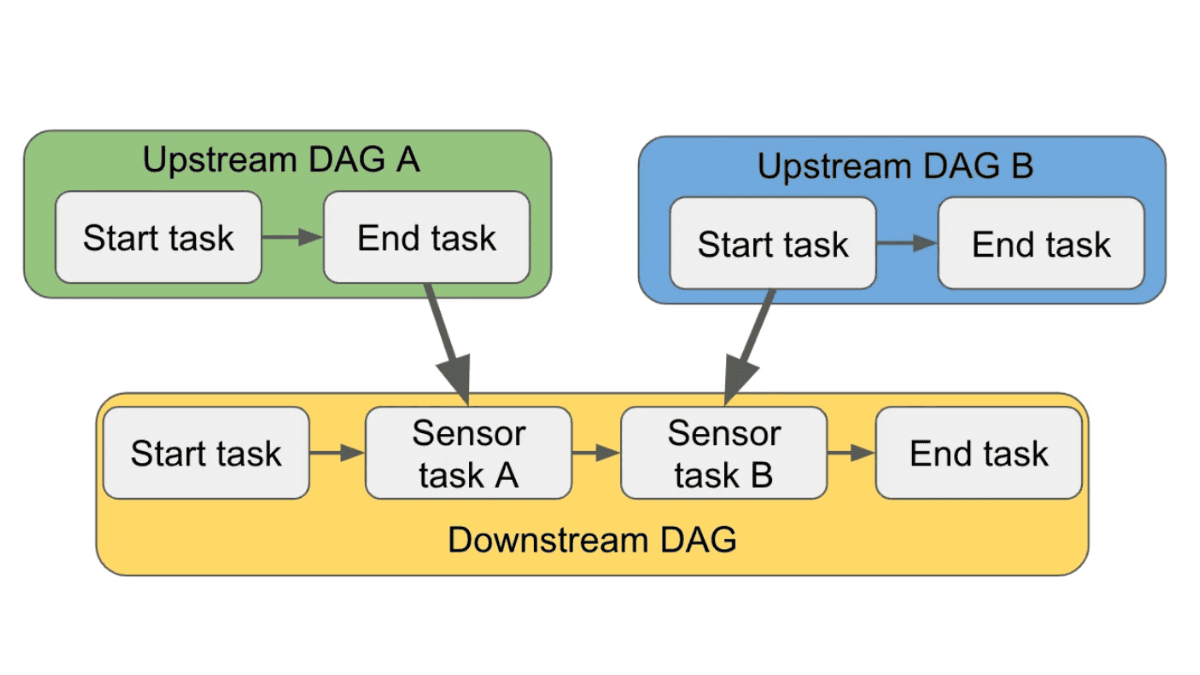
Kreuz-DAG-Abhängigkeiten in Apache Airflow: Ein umfassender Leitfaden
Vier Methoden zur effektiven Verwaltung und Skalierung Ihrer Datenworkflow-Abhängigkeiten mit Apache Airflow erkunden.

Daten mit Spark und Iceberg einfügen bzw. aktualisieren
Verwenden Sie die MERGE INTO-Syntax von Spark und Iceberg, um täglich inkrementelle Schnappschüsse einer veränderlichen Quelltabelle effizient zu speichern.
Wie wir unsere Docker-Bauzeiten um 40 % reduziert haben
Dieser Beitrag beschreibt zwei Möglichkeiten, das Erstellen Ihrer Docker-Images zu beschleunigen: den Build-Info remote zu cachen und die Link-Option beim Kopieren von Dateien zu verwenden.
Die Bausteine erfolgreicher Daten-Teams
Während meiner 7-jährigen Erfahrung im Bereich Daten habe ich in mehreren Datenteams gearbeitet, von denen einige erfolgreich waren, andere jedoch...
How to organize a data team to get the most value out of data
Offensichtlich ist: Ein Datenteam ist dazu da, dem Unternehmen Wert zu bringen. Aber ist das so offensichtlich? Haben Unternehmen nicht zu oft ein…
Wir befähigen Unternehmen wie Ihres
Die besten Unternehmen treiben die digitale Prozessadoption mit Dataminded voran.
ML Skalierbarkeit
Introducing cloud for doing ML training at scale

Cloud-Datenplattform
Scaling advanced analytics to continuously improve customer experience of media products


SAAS-Produkt
Ein SaaS-Produkt auf AWS einrichten. Die Skalierbarkeit der Cloud nutzen, um der Kundennachfrage gerecht zu werden.

Was unsere Kunden sagen
Ziehen Sie Hunderte von Unternehmen aller Größen und Branchen an, die mit uns große Verbesserungen erzielt haben.

„Der Erfolg, mein Problem schnell und effizient zu lösen, und die Freundlichkeit und Hilfsbereitschaft machten die Erfahrung noch besser.“

Ryan Call
Kreativdirektor @Placeholder

„Ihr Team war in der Lage, die effektivsten Keywords zu identifizieren und Anzeigen zu erstellen, die direkt mit unserer Zielgruppe sprachen.“

Jenny Wilson
CEO Gründer

„Der Erfolg, mein Problem schnell und effizient zu lösen, und die Freundlichkeit und Hilfsbereitschaft machten die Erfahrung noch besser.“

Dave Debryne
Kreativdirektor @Placeholder
„Der Erfolg, mein Problem schnell und effizient zu lösen, und die Freundlichkeit und Hilfsbereitschaft machten die Erfahrung noch besser.“
Ryan Call
Kreativdirektor @Placeholder
„Ihr Team war in der Lage, die effektivsten Keywords zu identifizieren und Anzeigen zu erstellen, die direkt mit unserer Zielgruppe sprachen.“
Jenny Wilson
CEO Gründer
„Der Erfolg, mein Problem schnell und effizient zu lösen, und die Freundlichkeit und Hilfsbereitschaft machten die Erfahrung noch besser.“
Dave Debryne
Kreativdirektor @Placeholder
Steigern Sie Ihr Geschäft mit Dataminded
Mach den ersten Schritt in Richtung deiner Laufziele




Sichere dir jetzt deinen Platz!
ML Skalierbarkeit
Introducing cloud for doing ML training at scale
Cloud-Datenplattform
Scaling advanced analytics to continuously improve customer experience of media products
SAAS-Produkt
Ein SaaS-Produkt auf AWS einrichten. Die Skalierbarkeit der Cloud nutzen, um der Kundennachfrage gerecht zu werden.